One of the little known options when using “Bare Metal” Foundation is doing so over a layer 3 network, instead of the traditional “same layer 2 network + MAC address” method.
This allows Foundation imaging of Nutanix nodes over a (good!) WAN link or across different subnets in your DC for example.
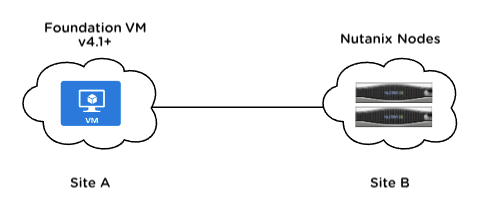
This method can be used to remotely ‘Bare Metal’ any hardware vendor platform running Nutanix via IPv4 – Nutanix NX, Lenovo HX, Dell XC, Software Only Cisco and HPE and others.

Quick Summary of the “Remote Bare Metal Foundation” procedure:
- Rack and cable the nodes, and configure the IPMI ports on the network with an IPv4 address (eg. via BIOS see below). Do this first.
- Deploy the Foundation VM on the network – ensuring it has IPv4 connectivity to the IPMI ports. The VM does not need to be on the same subnet as the IPMI ports and could be in a different site over a WAN.
- Go through the Bare Metal install process via the Foundation VM, skipping discovery and instead manually adding blocks/nodes via selecting the “I have configured their IPMIs to my desired IP addresses” option.
Critical Note on WAN Bandwidth Requirements
With this method you will copy AOS + Hypervisor image files over the network in parallel to each and every node – so consider available bandwidth and network utilisation as well as the AOS / Hypervisor image sizes that will be transferred from your Foundation VM to the nodes during the imaging process.
These files can be several GB in size. Foundation pushing images to nodes will time out after 15 minutes – so you will likely need a WAN link minimum of 50Mbit/s to copy the 4GB AOS file to a SINGLE node…and a better link if you are changing to ESXi (additional ~350MB) or HyperV (additional ~4GB) or if you are imaging more than one node.
If you have 4 nodes – multiply that by 4 of course. Clearly, this method is not for your small branch ROBO link. Use a tool like https://techinternets.com/copy_calc to see if your WAN link can handle the workload within that timeframe.
At time of writing you cannot modify the timeout setting.
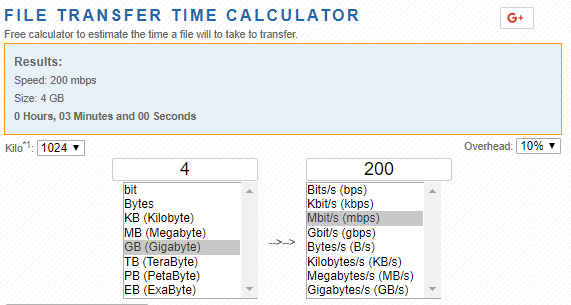
In summary, ensure your network link is capable of respecting the timeout value taking into account the number of nodes you are imaging. For example, if you were imaging 4 nodes over the WAN, you will be copying at least 16GB in total over that link within 15 minutes.
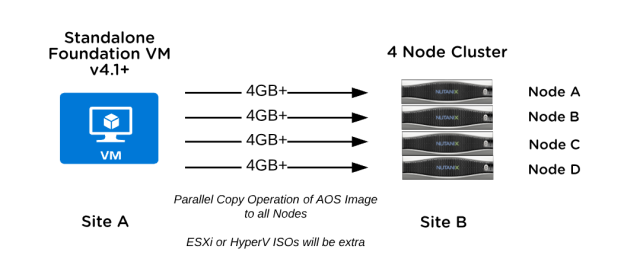
If you had a 1Gbit link (or local 1 Gbit switch), 20 nodes would take ~12 minutes just for the AOS images. If you are imaging HyperV nodes, you could only image 10 nodes (as you need to include the 4GB HyperV ISO as well) on 1Gbit links. This is why old 100Mbit switches or USB adapters won’t suffice when you are imaging multiple nodes.
Site A and Site B can be different L3 subnets. Make sure Site A’s Foundation VM subnet and Site B’s IPMI subnet and Site B’s CVM/Hypervisor subnet are all routable to each other. That is, every subnet involved must be routable to each other.
Setting the IPMI Ports Manually
If you are unsure how to set the IPMI IP addresses manually, see “Setting IPMI Static IP Address” section in the Foundation Field Installation Guide for instructions for configuring via BIOS on each node. The Foundation Field Installation Guide can be found on the Nutanix Support Portal.
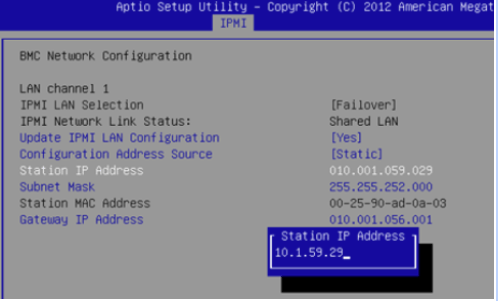
The above screenshot is from one node’s IPMI settings via BIOS. You would repeat this for each and every node you want to deploy, then use Foundation to image the nodes.
Quick UI Walkthrough
Below is a walkthrough of the initial screens in Foundation v4.1 for the Bare Metal via IPv4 process. Note that the IPMI addresses you type should match the IP addresses you’ve manually assigned to the nodes of course :
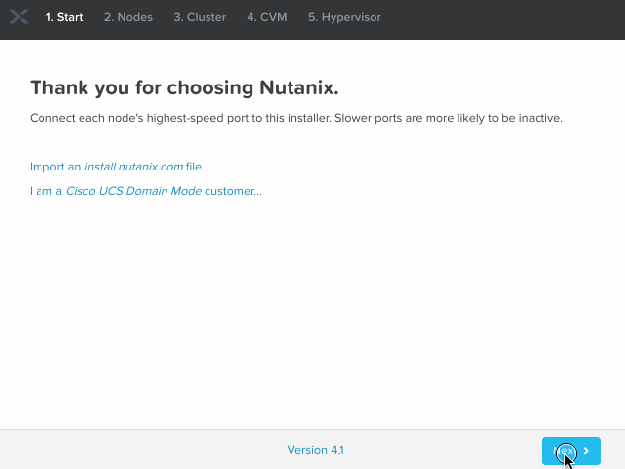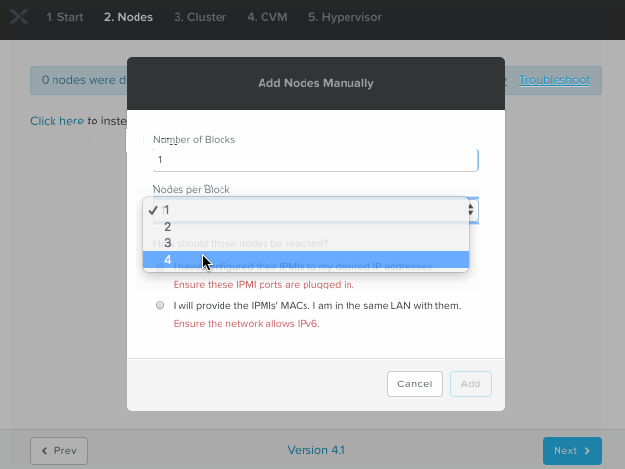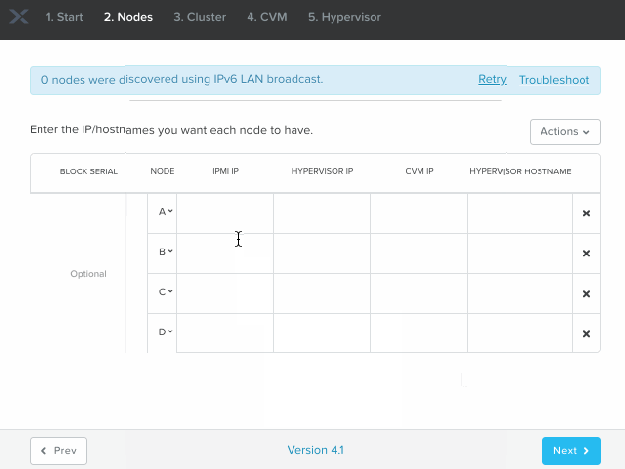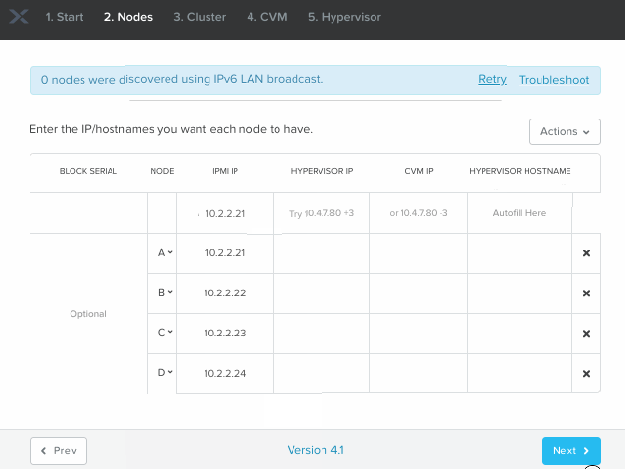
We are also developing a “Foundation Central” microservice within Prism Central which will allow for ‘zero touch’ deployments at scale, including using a local (to the nodes) file store to avoid pushing files over the WAN – but for now this ‘bare metal’ method works if you have the luxury of bandwidth.

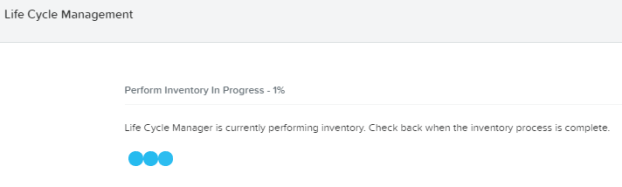
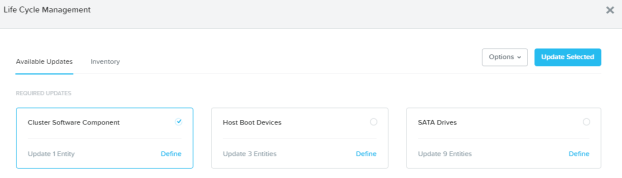
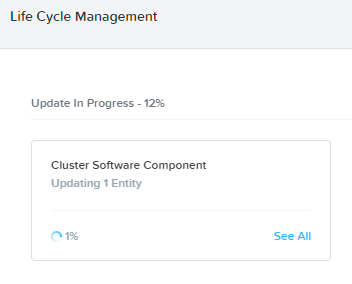
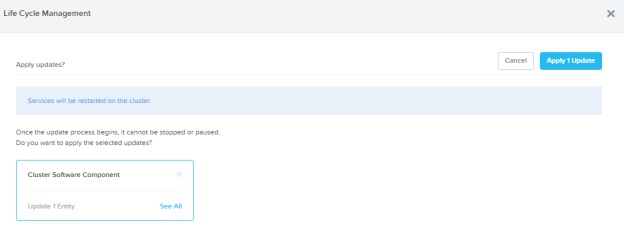 Run that update. You will see a message that “Services will be restarted” – meaning the Nutanix internal services will restart (LCM related) – but this is a non disruptive operation to your workloads so it is safe to run this update anytime. Once you hit the “Apply 1 Update” button, update process starts.
Run that update. You will see a message that “Services will be restarted” – meaning the Nutanix internal services will restart (LCM related) – but this is a non disruptive operation to your workloads so it is safe to run this update anytime. Once you hit the “Apply 1 Update” button, update process starts.