
With remote working now the new normal, it is challenging to send skilled IT professionals to data centers to install new equipment. Although Nutanix clusters have always been quick to install and configure, there was still a requirement to send a trained IT technician to site to run the Foundation software for deployment, usually connected to a local laptop. For large-scale or multiple sites, this can be a costly exercise.
How could we make this even easier in a ‘work from home’ world?
With the launch of Nutanix Foundation Central 1.0 with Prism Central 5.17, this specialist requirement is now removed.
Zero-touch deployments are now a reality for factory-shipped appliances from Nutanix, Lenovo, HPE, Dell, Fujitsu, and Inspur…. all will be Foundation Central ready out of the box.
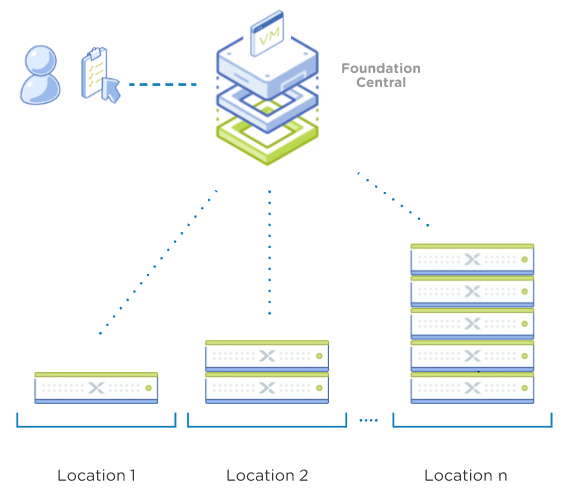
Nutanix Foundation Central is a service on Prism Central 5.17+
Foundation Central (FC) is an at-scale orchestrator of Nutanix deployment and imaging operations. After the initial network prerequisites are met, new nodes ordered from the factory can be connected to the network and receive Foundation Central’s IP address via DHCP assignment. Since nodes are shipping from the factory, they will have either a functional CVM (running the CVM Foundation service) or DiscoveryOS (for NX International shipments) inbuilt.
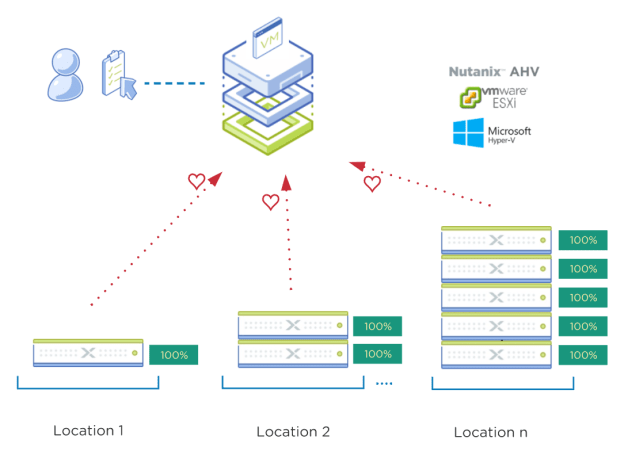
The nodes (no matter the location) send their “I’m ready” heartbeat status to Foundation Central.
“Location” can be within the same Data Center and/or a remote site as an example.
Once the nodes are detected by Foundation Central, the administrator can create a deployment task and then send that task to the locations and the configuration job is conducted by the nodes themselves. The nodes send their job status back to Foundation Central for the administrator to monitor.

Foundation Central Home Screen with 15 discovered nodes. Nodes can be running different AOS and/or Hypervisor and can be re-deployed into clusters with a new AOS/Hypervisor of choice
Foundation Central never initiates a connection to the nodes. The nodes are the source for all communications and are awaiting to receive their orders on what task to do.
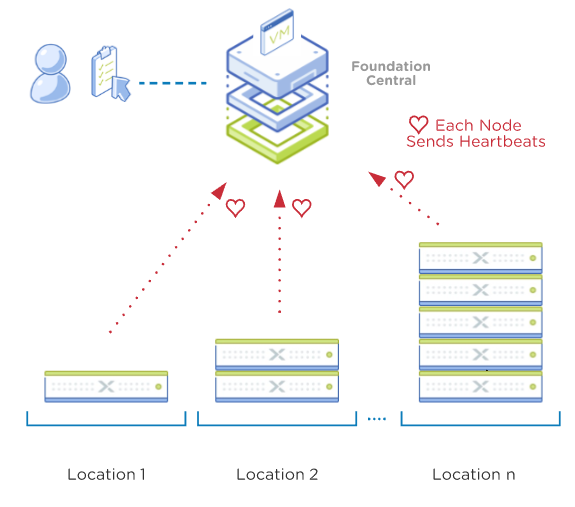
Unconfigured nodes send heartbeats to Foundation Central
Foundation Central receives these node heartbeats and then will display the nodes as available to be configured. By default this could take up to 20 minutes to appear in the Foundation Central UI. Heartbeats are sent until the nodes are configured and part of a formed cluster.

Unconfigured nodes send requests to FC and receive their configuration orders
Foundation Central is only receiving status updates until job completion. It receives these status updates from the coordinating node.
After a successful configuration/re-imaging process is done on one node, the original ‘coordinating node’ hands over to that new 100% completed node, and now this node takes over as the new (permanent) coordinating node for the remaining nodes.
If re-imaging to a different AOS or Hypervisor is required, Foundation Central will ask for the URL where these images can be found. These can be anywhere on the network, but given the file size it is recommended they be local to the nodes where possible.

Changing AOS and Hypervisor Type if required
Once the administrator configures the Foundation Central jobs as desired, Foundation Central will await the specified nodes to request their configuration task.
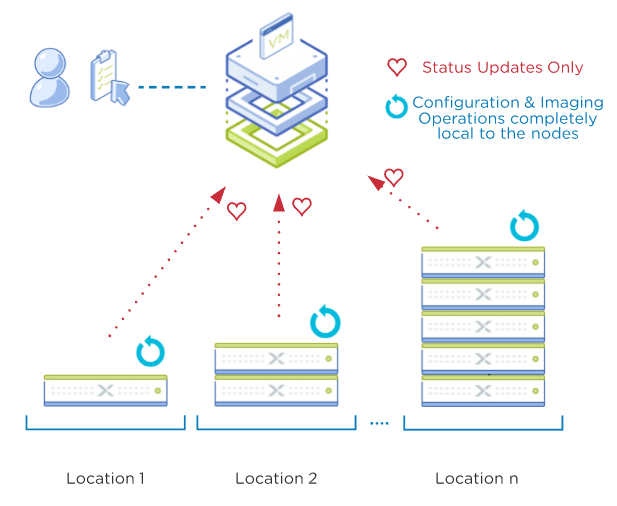
Imaging and Configuration tasks are always local to the nodes/location
Configuration tasks are then fully handed off to the local nodes and Foundation Central becomes a ‘passive partner’ in the process from here. The nodes elect a ‘coordinating node’ for the entire operation and will be responsible for keeping Foundation Central updated on the status of the tasks.
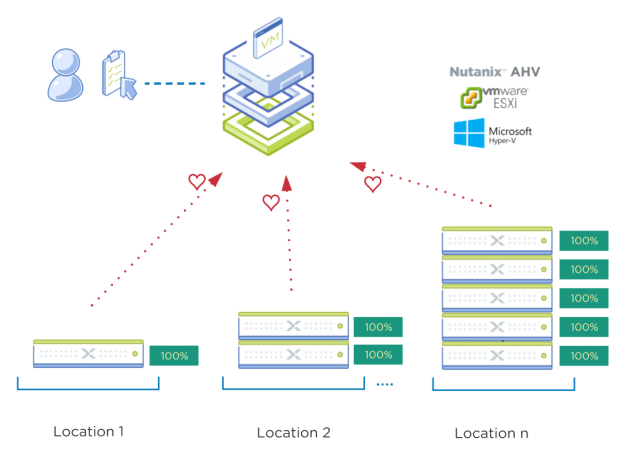
Deployment Complete in parallel with different AOS/Hypervisors no matter the location
Foundation Central Requirements
- Nodes must be running Foundation 4.5.1 or higher (bundled with a CVM or DiscoveryOS). It is advisable to run the latest Foundation on the nodes
(upgrade using APIs is very easy before imaging) - Networking requirements must be met (see below)
- Prism Central must be minimum version 5.17
Networking and DHCP Requirements to use Foundation Central
The factory nodes need to be connected to a network that has a DHCP scope defined which allows for specific DHCP options. This is to ensure the nodes automatically receive the Foundation Central IP address and API keys specific to your environment.
- DHCP server must be present and must be configured with vendor-specific-options:
Vendor class: NutanixFC
Vendor encapsulated options (DHCP option 43):- Option code: 200, Option name: fc_ip
- Option code: 201, Option name: api_key
- L3 connectivity from remote nodes to Foundation Central must be available
- L3 connectivity between ‘starting’ and ‘destination’ subnets if IP addresses are to be changed as part of the node configuration process
- Remote CVMs must be configured in DHCP mode (default from factory)
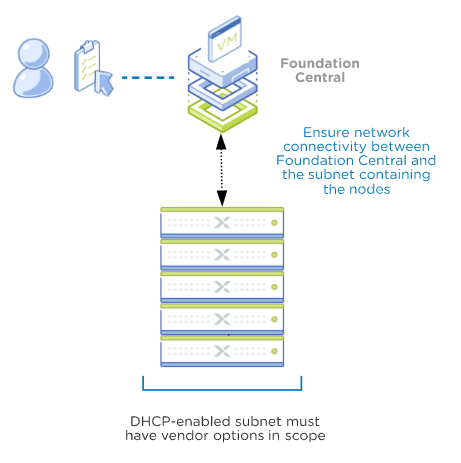
Option 1: Nodes are discovered and configured to remain in the same subnet
The factory nodes need to be connected to a network that has a DHCP scope defined which allows for specific DHCP options. This is to ensure the nodes automatically receive the Foundation Central IP address and API keys specific to your environment.
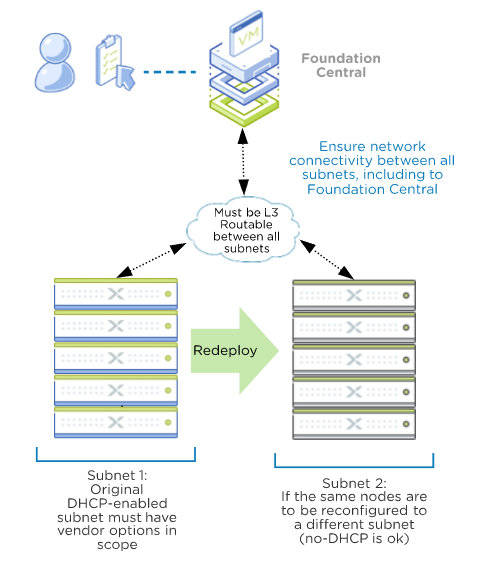
Option 2: Nodes will be re-deployed to a different subnet. DHCP is not required for the 2nd subnet.
For more information contact your Nutanix SE or check the Foundation Central Guide on the Nutanix Support portal.
Special thanks to Foundation Engineering (Toms, Monica, Toshik, YJ and extended team) for the development of Foundation Central…they are already working on some improvements for v1.1 !
Please reach out with any feedback or suggestions and I trust this helps in making your working-from-home life a little easier.


