“Single Pane of Glass” gets thrown around a lot by vendors …. as does “upgrades are easy”. If you lucky enough to be a Nutanix customer, you already live this dream.
But how could the Nutanix Engineering team make the experience even better?
While Hugh was using the tried-and-true traditional Nutanix AOS upgrade method within Nutanix Prism, each individual component (such as AOS, hypervisor, BIOS etc) had to be done independently. It was reliable of course, but what if you wanted to upgrade many components of your cluster at once and it be just as easy and reliable and to take care of the dependencies for you?
Plus, with security releases coming thick and fast these days, it is imperative that we try to make it dead simple for customers like Hugh to be able to react quickly to patch their infrastructure, regardless of hypervisor or hardware component type.
Thus, Nutanix Life Cycle Manager (LCM) was born.
The LCM feature is available with Nutanix AOS 5.0+
LCM is a framework that can detect and upgrade hardware and software components in a rolling fashion completely in-band via Nutanix Prism, taking care of any dependencies and maintenance mode operations as needed to conduct the upgrades.
The idea is that you can go to the one location to manage all your Nutanix related software and firmware updates, click a button and then LCM will orchestrate the entire process, with no effect on your running workloads. All this while you go and do something else in the meantime, or perhaps just have a quiet glass of red.
LCM has the power to tell whatever brand of hypervisor you are using to evacuate VMs to other nodes and reboot the host should the update require it. Only when a host is confirmed that it has returned to service is the next host able to conduct it’s upgrade.
LCM is intelligent enough to allow you to select one node only for some updates. For example, you might want to just upgrade the BIOS or disks firmware in one node. Some updates are cluster wide and some can be node based depending on the component – but in either case LCM will take care of the operation for you.
If you are not familiar with Nutanix LCM, then take a look at the quick video demos :
LCM is the framework which (eventually) will be the method in which you manage updates and upgrades to your Nutanix clusters. I say ‘eventually’ because it is still early days for LCM, but things are ramping up quickly. As such, you should check for new LCM updates every week and see which new features are unlocked with the latest LCM Framework updates.
You don’t have to wait for a new version of the Nutanix AOS software either – LCM is independent of AOS – so you can upgrade LCM at any time a new update is available.
So what’s new in LCM v1.2?
With v1.2, LCM supports additional inventory and update components on Nutanix NX and Dell XC clusters. Lenovo HX and Nutanix Software-Only support is under development. Up to now, only the SATADOM updates were supported.
The following has been added in LCM v1.2:
Nutanix NX and SX Platform LCM support requires AHV or ESXi 5.5, 6.0, or 6.5 and supports updates to the following components : HDD, SSD and NVMe drives.
Dell XC Platform LCM support requires ESXi 5.5 and 6.0 and AOS 5.1.0.3 or newer and supports updates to the following XC components: XC BIOS, XC iDRAC, XC HBA controller, XC NIC, XC Disks (SSD and HDD).
For more details, check the release notes on the Nutanix Support Portal.
Using LCM
If you’ve not had a look at LCM before, I suggest you update the LCM Framework to the latest version, run an ‘Inventory’ (discovery) job and take a look around.
It is a good idea to run a ‘Perform Inventory’ operation first. This will scan your cluster and check if there are any updates available for any components, including the LCM Framework itself.
Go to the LCM page and select Options->Perform Inventory. The status will change to “Perform Inventory in Progress” which takes a few minutes as your whole cluster is scanned.
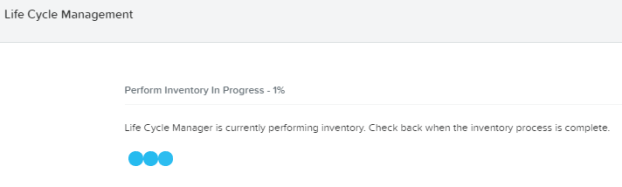
You may see some available updates:
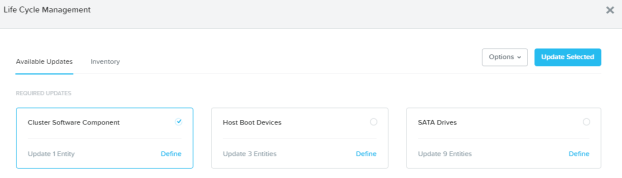
You can see that the above screenshot shows software and some hardware components that have available updates. In order to update LCM to the latest, I’ll select (and update) the ‘Cluster Software Component’ and hit the ‘Update Selected’ button.
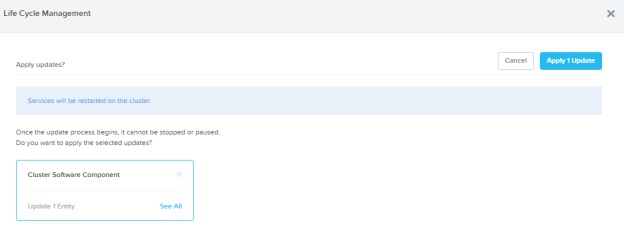 Run that update. You will see a message that “Services will be restarted” – meaning the Nutanix internal services will restart (LCM related) – but this is a non disruptive operation to your workloads so it is safe to run this update anytime. Once you hit the “Apply 1 Update” button, update process starts.
Run that update. You will see a message that “Services will be restarted” – meaning the Nutanix internal services will restart (LCM related) – but this is a non disruptive operation to your workloads so it is safe to run this update anytime. Once you hit the “Apply 1 Update” button, update process starts.
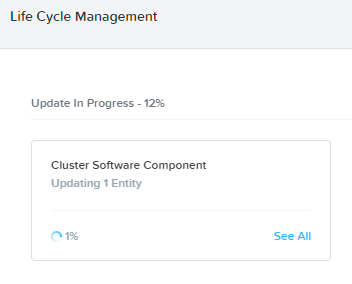
Once the new update to LCM is installed, run Perform Inventory again to see if there are any new updates or components supported in the new version (now that you’ve updated the LCM Framework, there may be some more unlocked features).
If there are any other updates available, you may choose to update them as well using the same logic.
Future Plans
In the coming months you will see more unlocked updates appear in LCM, including broader hypervisor support, more hardware component support, more Nutanix software support (eg. NCC, Foundation etc) so that the current “Upgrade Software” menu will eventually be retired and LCM takes over all functions related to our “1-Click Upgrades”.
LCM in Prism Central will also launch in 2018, with the ability to expand LCM to handle upgrades across multiple clusters.
In the meantime, the LCM Engineering team would love to hear your suggestions and feedback. They also love twitter mentions, so please keep them coming.