


Spot on! Invisible Infra means not babysitting old DC constructs, instead deliver *business* advantages. Source: https://twitter.com/vjswami/status/562298721942401026
If you make the claim that your DC infrastructure should be invisible, clearly you need to have a solid story around handling failures. Coping with failure scenarios is critical in any infrastructure. I get asked often on how Nutanix clusters cope in situations where things go wrong unexpectedly – and rightly so.
Nutanix has been designed to expect failures of hardware, hypervisor or Nutanix’s own NOS software. I don’t care how long it takes to deploy a Nutanix cluster (5 mins or 60 mins depending if you want to change hypervisor etc) – as to me that is a one-off occurrence and fairly uninteresting (although a lot faster than the old way of deploying servers and a SAN). What really matters is whether or not you are going to be called in at 2am or on weekends when things die – or even worse if something goes wrong at 9am on a weekday.
In my personal view, uptime trumps all else in this modern 24×7 world. Gone are the days where ‘outage windows’ are acceptable. Of course, every deployment is unique and depends on the requirements and circumstances.
I usually demo HA events (eg. motherboard failure, nic failure etc) but none of that is particularly exciting for virtualisation administrators – failures of this nature are *expected* to be handled OK in 2015. Nutanix is no different here as that is all handled by the hypervisor.
One demo that really gets people excited is what I want to talk about here.
I’m going to assume you know a little about the Nutanix terminology and architecture, if you don’t check out The Nutanix Bible by Steven Poitras : http://stevenpoitras.com/the-nutanix-bible/
To set the scene, we have a fully working NX-3450 block (4 nodes of 3050 series) – which is a 2U appliance. These four nodes will be connected to a standard 10GbE switch. The Nutanix architecture is such that there is a Controller VM (CVM) on each and *every* node in the cluster (here a NX-3450 would therefore have 4 CVMs). This setup gives approx 7.5TB usable (after replication) but before dedupe/compression/EC.
With Nutanix, the storage fabric and the compute fabric are independent of each other. For example, you can upgrade one without affecting the other. Therefore the failure domain is limited to one or the other.
Let’s focus on a single CVM on a node that is also hosting your guest VMs. Let’s assume that the hypervisor is healthy and OK. What if someone powers off the CVM hard by mistake, or deletes the CVM, or if the CVM kernel panics and simply “stops” in the middle of normal guest VM I/O operations? What are the effects? What will your users notice? Will all hell break loose? Let’s check out this worst case scenario up-front, where the Nutanix “Data Path Redundancy” feature kicks into action.
I’ll demo this via this short video:
So what happened here? The CVM was killed with live guest VMs reading and writing data. This is NOT a usual scenario – but it is a great example of the robustness of the Nutanix distributed fabric. What we see is that the hypervisor is trying to write to the NFS datastore. When the CVM dies, the hypervisor on that node can no longer communicate with the NFS datastore and re-tries again and again. The hypervisor will continue to do so as per normal NFS timeout values. But here, the CVMs on other nodes were already taking steps to fix the situation – before the hypervisor knows what’s going on! After 30 seconds, the hypervisor on the affected node is told by one of the other CVMs to redirect I/O to one of the remaining healthy CVMs and things carry on as normal. This is well within the hypervisor’s (in this case ESXi 5.5) default NFS timeout period before it marks the NFS datastore as unavailable (125 seconds is mentioned here: http://cormachogan.com/2012/11/27/nfs-best-practices-part-2-advanced-settings/). Cool.
So what does all that mean to you and the end users of the guest VMs when a CVM is killed?
No data loss.
No loss in guest VM network connectivity.
No guest VM BSOD.
No hypervisor PSOD.
No vMotion / No HA event required.
….just a temporary 30 second ‘pause’ in I/O because the NFS datastore became unresponsive for 30 seconds – but it recovered before the hypervisor’s own timeout function – so the guests keep going from where they last tried to write data. Job done!
Obviously the same situation would be true if your Nutanix cluster was instead running Hyper-V (SMB) or Acropolis Hypervisor (iSCSI). Remember, to Nutanix the hypervisor itself is ‘above’ the distributed storage fabric (designed deliberately so). If it wasn’t then there would have needed to be a full outage of the VMs and a HA event.
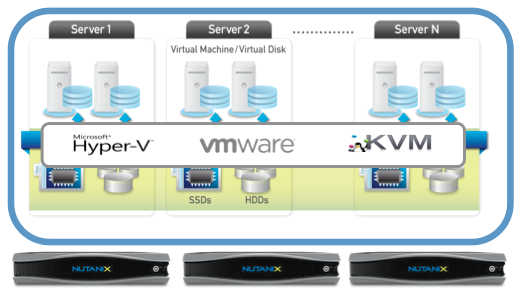
Abstracting the physical disks away from the hypervisor means the Nutanix CVMs can present the protocol of choice to your hypervisor of choice. Treat storage just like a application VM….If virtualisation is good enough for production Oracle and SQL, then so it should be for storage (and it is :)
If you still are a bit hazy on how Data Path Redundancy works, check out this nu.school video: https://www.youtube.com/watch?v=9cigloapOXw
Please keep in mind that these I/O ‘pause’ effects would not be seen in a normal scenario such as a rolling one-click upgrade of Nutanix NOS software versions – where there would be no interruption of I/O at all (due to the fact the affected CVM can pro-actively redirect it’s hypervisor I/O to another CVM in preparation for a controlled reboot). The same is true for the 1-click hypervisor upgrades – because the guest VMs are vMotioned anyway before CVM shutdown (because the hypervisor itself is restarted).
This is why people can expand/upgrade their production Nutanix clusters in the middle of the day:


Very cool stuff. I remember wasting a Christmas Day in 2008 upgrading firmware on an old IBM blade chassis. I wish Nutanix had existed then…. I could have done the same on Nutanix nodes over Christmas lunch…from home!
BTW, don’t worry if you have more nodes (than the 4 shown in the video) or want more protection than simply handling a single CVM failure. If you have enough nodes or appliances you can lose entire blocks or racks of Nutanix and keep working (ie. lose more than one CVM simultaneously). Check out the Nutanix Bible for ‘Availability Domains’ and RF3 for examples and check the minimum requirements for these situations. Try that with a dual-controller SAN.
I hope this post has shown you one of the most powerful aspects of a building your virtualisation infrastructure using Nutanix. In a lot of traditional environments, losing 6 disks at once would mean you’d be having a very bad day, maybe even having to invoke a DR strategy or restore from backups, perhaps with a lot of manual steps too. Who needs that drama in 2015? Go invisible and then go home and crack open a beer! Let the software do all the work for you, and with your free time you could maybe learn some new skills instead of babysitting infrastructure. Win/win!
Thanks to Josh Odgers (@josh_odgers), Matt Northam (@twickersmatt) and Matt Day (@idiomatically … a champion Nutanix customer!) for reviewing this post.

I think you have the best blog I have ever read. No BS, straight dope! Keep them coming.